java基础数据类型 假设一个值是29.7,我们把它强转成一个char,那么结果值到底是 30 还是29 呢? 构造函数 垃圾收集 成员初始化 public, protected, default(friendly), private 对应的访问权限 final 方法过载与覆盖 抽象方法 接口 多重继承 多态 继承和 finalize() 构建器内部的多形性方法的行为 集合
java的I/O 线程
二、内容 java基础数据类型:int, float, double, boolean, short, long, byte以及char .1
2
3
4
cahr a = 'a'; // 必须限定长度为一个字节。等效于 char a = 97; 因为'a'在ASCII码表里对应97.
char b = '中文';
char c = 97;
System.out.println(a == c); // true
将一个 float 或 double 值造型成整数值后,总是将小数部分“砍掉”,不作任何进位处理。所以结果是29.
返回目录 自动调用 的,我们不能在程序中像调用其他方法一样去调用构造方法(必须通过关键词new自动调用它 )。注意!
构造器里通过this调另一个构造器,只能调用一个,不能调用两个。
除构造器之外的方法不能调用构造器。
返回目录
垃圾收集并不等于“破坏”!
我们的对象可能不会当作垃圾被收掉!
垃圾收集只跟内存有关!
不必过多地使用finalize()。它并不是进行普通清除工作的理想场所。finalize()最有用处的地方之一是观察垃圾收集的过程。
返回目录 1
2
3
4
void f() {
int i;
i++;
}
上述代码会报错,提示未初始化。但是这样改:1
2
3
4
5
6
7
public class InitialValues {
private int i;
public static void main(String[] args) {
InitialValues initialValues = new InitialValues();
System.out.println(initialValues.i); // 0
}
}
能正常运行且i有一个初始值0.
初始化顺序static (如果它们尚未由前一次对象创建过程初始化),接着是非static 对象,然后再构造器。
明确进行的静态初始化static关键字定义的变量以及代码块在类初始化的时候就执行了,属于静态资源。static关键字定义的内容也初始化一次。static修饰的内容在类第一次初始化后就当做静态资源暂存在java虚拟机上了,以后不管类初始化几次,都不会再对static修饰的内容初始化。static修饰的内容赋为它的被动属性,被动属性英雄出场自带,其他属性升级(类被实例化)才能学到。Cups,但却只打印一次Cup(1) Cup(2)。因为第一次初始化后,static修饰的内容就不会再度执行了。
看下面代码对比:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public class ExplicitStatic {
public static void main(String[] args) {
System.out.println("Inside main()");
Cups.c1.f(99);
}
static Cups x = new Cups();
static Cups y = new Cups();
}
class Cup {
public Cup(int marker) {
System.out.println("Cup(" + marker + ")");
}
void f(int marker) {
System.out.println("f(" + marker + ")");
}
}
class Cups {
static Cup c1;
static Cup c2;
static {
c1 = new Cup(1);
c2 = new Cup(2);
}
public Cups() {
System.out.println("Cups()");
}
}
上述代码最终打印如下:1
2
3
4
5
6
Cup(1)
Cup(2)
Cups()
Cups()
Inside main()
f(99)
但是如果把Cups类里面的static代码块前的static去掉,打印如下:1
2
3
4
5
6
7
8
Cup(1)
Cup(2)
Cups()
Cup(1)
Cup(2)
Cups()
Inside main()
f(99)
如果不进行Cups的实例化呢?static Cups x = new Cups(); static Cups y = new Cups();注释掉,会发现打印输出:1
2
3
4
Inside main()
Cup(1)
Cup(2)
f(99)
初始化一个类并不仅仅靠实例化,通过 类.属性名 或者 类.方法也可以对类进行初始化!
返回目录 public √ √ √ √ protected √ √ √ × default √ √ × × private √ × × ×
返回目录
final修饰的变量不能被重新赋值修改。final修饰的方法不能被继承类修改。final修饰的变量在定义时可以没有初始值,但是必须在构造器里赋值。final修饰的类不能被继承。final可以有效的关闭“动态绑定”。
返回目录
“过载”是指同一样东西在不同的地方具有多种含义;而“覆盖”是指它随时随地都只有一种含义,只是原先的含义完全被后来的含义取代了。
过载的例子:1
2
3
4
5
6
7
8
9
class A {
void play(int i) {}
}
class C {
C() {}
}
class B extends A {
void play(C c) {}
}
上面的例子中,B继承了A,A里面有方法play不过参数是int型的,而B里面的play方法参数却是C类型的,这里并不是覆盖A类里面的play方法,而是新增了一个使用C类型参数的play方法。
返回目录 abstract void X();abstract(抽象)。否则,编译器会向我们报告一条出错消息。
当继承抽象类时,子类必须将抽象类的抽象方法全部显式的写出来,否则报错。
返回目录
返回目录 implements 关键字的后面,并用逗号分隔它们。可根据需要使用多个接口,而且每个接口都会成为一个独立的类型,可对其进行上溯造型。下面这个例子展示了一个“具体”类同几个接口合并的情况,它最终生成了一个新类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import java.util.*;
interface CanFight {
void fight();
}
interface CanSwim {
void swim();
}
interface CanFly {
void fly();
}
class ActionCharacter {
public void fight() {}
}
class Hero extends ActionCharacter implements CanFight, CanSwim, CanFly {
public void swim() {}
public void fly() {}
}
public class Adventure {
static void t(CanFight x) { x.fight(); }
static void u(CanSwim x) { x.swim(); }
static void v(CanFly x) { x.fly(); }
static void w(ActionCharacter x) { x.fight(); }
public static void main(String[] args) {
Hero i = new Hero();
t(i); // Treat it as a CanFight
u(i); // Treat it as a CanSwim
v(i); // Treat it as a CanFly
w(i); // Treat it as an ActionCharacter
}
}
返回目录
三个必要条件:继承 、重写 、父类引用指向子类对象 。
以下内容来自知乎! Overload。1
2
void foo(String str);
void foo(int num);
父类与子类有同样的方法名和参数,这叫方法覆盖。Override。1
2
3
4
5
6
7
8
9
10
class Parent {
void foo() {
System.out.println("Parent foo()");
}
}
class Child extends Parent {
void foo() {
System.out.println("Child foo()");
}
}
父类引用指向子类对象,调用方法时会调用子类的实现,而不是父类的实现,这叫多态。1
2
Parent instance = new Child();
instance.foo(); // 此处其实调用的是 Child 类里面的 foo()
拓展深入理解下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Animal {
int num = 10;
static int age = 20;
public void eat() {
System.out.println("动物吃饭");
}
public static void sleep() {
System.out.println("动物在睡觉");
}
public void run() {
System.out.println("动物在奔跑");
}
}
class Cat extends Animal {
int num = 80;
static int age = 90;
String name = "tomCat";
public void eat() {
System.out.println("猫吃饭");
}
public static void sleep() {
System.out.println("猫在睡觉");
}
public void catchMouse() {
System.out.println("猫在抓老鼠");
}
}
测试类Demo_Test1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Demo_Test1 {
public static void main(String[] args) {
Animal am = new Cat();
am.eat();
am.sleep();
am.run();
// am.catchMouse(); 报错,Animal类里没有这个方法。
// System.out.println(am.name); 报错
System.out.println(am.num);
System.out.println(am.age);
}
}
// 打印输出
猫吃饭
动物在睡觉
动物在奔跑
10
20
由上述例子可以看出:
子类 Cat 中重写或者覆盖了父类 Animal 中的 eat(),所以打印输出了 猫吃饭。
子类 Cat 中虽然也重新对父类Animal中的 sleep() 进行重写,但是输出发现并未覆盖掉父类的方法。仔细观察发现,该方法是静态的,不会被覆盖 。
子类 Cat 中虽然也重新对父类Animal中的 num 和 age 进行赋值期望覆盖父类,但是由于age也是静态的,依旧不能被覆盖。不过需要着重关注的是num,该变量不是静态的,也没有用final修饰,却依然未被覆盖 。
上述代码中有两处报错,分别是子类定义的name变量以及catchMouse()!am声明时是Animal类型,虽然给它赋值了Cat类型并没有报错,但那是因为Cat类型继承自Animal类型,所以可以赋值。不过,am的本质依然是Animal类型而不是Cat类型,Animal类型中并没有name变量以及catchMouse(),所以会报错 。
那么可以总结出多态成员访问的特点:成员变量 成员方法 静态方法 只有非静态成员的方法,编译才看左边,运行看右边。
从上述例子可以看出,多态有一个弊端即无法访问子类定义的方法和变量。强转 1
2
3
Cat ct = (Cat)am;
ct.catchMouse();
System.out.println(ct.name);
返回目录 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
package com.lizz.finalize;
public class Frog extends Amphibian {
Frog() {
System.out.println("Frog()");
}
protected void finalize() {
System.out.println("Frog finalize");
if(DoBaseFinalization.flag) {
try {
super.finalize();
} catch (Throwable e) {
}
}
}
public static void main(String[] args) {
if(args.length != 0 && args[0].equals("finalize")) {
DoBaseFinalization.flag = true;
} else {
System.out.println("not finalizing bases");
}
new Frog();
System.out.println("bye!");
System.runFinalizersOnExit(true);
}
}
class DoBaseFinalization {
public static boolean flag = false;
}
class Characteristic {
String s;
Characteristic(String c) {
s = c;
System.out.println("Creating Character " + s);
}
protected void finalize() {
System.out.println("finalizing Characteristic " + s);
}
}
class LivingCreature {
Characteristic p = new Characteristic("is alive");
LivingCreature() {
System.out.println("LivingCreature()");
}
protected void finalize() {
System.out.println("LivingCreature finalize");
if(DoBaseFinalization.flag) {
try {
super.finalize();
} catch (Throwable e) {
}
}
}
}
class Animal extends LivingCreature {
Characteristic p = new Characteristic("has heart");
Animal() {
System.out.println("Animal()");
}
protected void finalize() {
System.out.println("Animal finalize");
if(DoBaseFinalization.flag) {
try {
super.finalize();
} catch (Throwable e) {
}
}
}
}
class Amphibian extends Animal {
Characteristic p = new Characteristic("can live in water");
Amphibian() {
System.out.println("Amphibian()");
}
protected void finalize() {
System.out.println("Amphibian finalize");
if(DoBaseFinalization.flag) {
try {
super.finalize();
} catch (Throwable e) {
}
}
}
}
// 打印输出:
not finalizing bases
Creating Character is alive
LivingCreature()
Creating Character has heart
Animal()
Creating Character can live in water
Amphibian()
Frog()
bye!
finalizing Characteristic can live in water
finalizing Characteristic has heart
finalizing Characteristic is alive
Frog finalize
仔细观察代码和后4个输出,发现输出顺序是从最低级的子类不断往上一直到基础类 ,也就是说finalize()是从最下面的子类不断向上调用的。
返回目录
设计构建器时一个特别有效的规则是:final 属性的那些方法(也适用于private方法,它们自动具有final 属性)。
若调用构建器内部一个动态绑定的方法,会使用那个方法被覆盖的定义 。然而,产生的效果可能并不如我们所愿,而且可能造成一些难于发现的程序错误。在任何构建器内部,整个对象可能只是得到部分组织——我们只知道基础类对象已得到初始化,但却不知道哪些类已经继承。然而,一个动态绑定的方法调用却会在分级结构里“向前”或者“向外”前进。它调用位于衍生类里的一个方法。 如果在构建器内部做这件事情,那么对于调用的方法,它要操纵的成员可能尚未得到正确的初始化——这显然不是我们所希望的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
package com.lizz.polymorphism;
public class PolyConstructors {
public static void main(String[] args) {
new RoundGlyph(5);
}
}
abstract class Glyph {
abstract void draw();
Glyph() {
System.out.println("Glyph() before draw()");
draw();
System.out.println("Glyph() after draw()");
}
}
class RoundGlyph extends Glyph {
int radius = 1;
RoundGlyph(int i) {
radius = i;
System.out.println("RoundGlyph.RoundGlyph(), radius = " + radius);
}
void draw() {
System.out.println("RoundGlyph.drwa(), radius = " + radius);
}
}
// 打印输出:
Glyph() before draw()
RoundGlyph.drwa(), radius = 0
Glyph() after draw()
RoundGlyph.RoundGlyph(), radius = 5
仔细观察上述代码以及输出,发现Glyph初始化调用构造器时,其内部的draw()并没有定义方法主体但是却打印输出了RoundGlyph类内部重写的draw()方法。
在采取其他任何操作之前,为对象分配的存储空间初始化成二进制零。
就象前面叙述的那样,调用基础类构建器。此时,被覆盖的draw()方法会得到调用(的确是在 RoundGlyph 构建器调用之前),此时会发现 radius 的值为 0,这是由于步骤(1)造成的。
按照原先声明的顺序调用成员初始化代码。
调用衍生类构建器的主体。
返回目录
当我们编写程序时,通常并不能确切地知道最终需要多少个对象。有些时候甚至想用更复杂的方式来保存对象。为解决这个问题,Java 提供了四种类型的“集合类”:Vector(矢量)、BitSet(位集)、Stack(堆栈)以及Hashtable(散列表) 。所有Java 集合类都能自动改变自身的大小 。
代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package com.lizz.set;
import java.util.Vector;
public class CatsAndDogs {
public static void main(String[] args) {
Vector cats = new Vector();
for(int i = 0; i < 7; i++) {
cats.addElement(new Cat(i));
}
cats.addElement(new Dog(7));
for(int i = 0; i < cats.size(); i++) {
((Cat)cats.elementAt(i)).print();;
}
}
}
class Cat {
private int catNumber;
Cat(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat #" + catNumber);
}
}
class Dog {
private int dogNumber;
Dog(int i) {
dogNumber = i;
}
void print() {
System.out.println("Dog #" + dogNumber);
}
}
可以看出,Vector 的使用是非常简单的:先创建一个,再用 addElement()置入对象,以后用 elementAt()取得那些对象(注意 Vector 有一个 size()方法,可使我们知道已添加了多少个元素,以便防止误超边界,造成违例错误)。Cat 和 Dog 类都非常浅显——除了都是“对象”之外,它们并无特别之处(倘若不明确指出从什么类继承,就默认为从 Object 继承)。所以我们不仅能用 Vector 方法将 Cat 对象置入这个集合,也能添加 Dog 对象,同时不会在编译期和运行期得到任何出错提示。用Vector 方法elementAt()获取原本认为是Cat 的对象时,实际获得的是指向一个Object 的引用,必须将那个对象转型为Cat。
返回目录 Vector 有一个缺陷:需要事先知道集合的准确类型,否则无法使用。乍看来,这一点似乎没什么关系。但假若最开始决定使用Vector ,后来在程序中又决定(考虑执行效率的原因)改变成一个 List (属于 Java1.2 集合库的一部分),这时又该如何做呢?Iterator )的概念达到这个目的。它可以是一个对象,作用是遍历一系列对象,并选择那个序列中的每个对象,同时不让客户程序员知道或关注那个序列的基础结构。此外,我们通常认为反复器是一种“轻量级”对象;也就是说,创建它只需付出极少的代价。但也正是由于这个原因,我们常发现反复器存在一些似乎很奇怪的限制。例如,有些反复器只能朝一个方向移动。Enumeration (枚举,注释②)便是具有这些限制的一个反复器的例子。除下面这些外,不可再用它做其他任何事情:elements()的方法要求集合为我们提供一个 Enumeration。我们首次调用它的 nextElement()时,这个Enumeration 会返回序列中的第一个元素。nextElement() 获得下一个对象。hasMoreElements()检查序列中是否还有更多的对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
package com.lizz.set;
import java.util.Enumeration;
import java.util.Vector;
public class CatsAndDogs2 {
public static void main(String[] args) {
Vector cats = new Vector();
for(int i = 0; i < 7; i++)
cats.addElement(new Cat2(i));
// Not a problem to add a dog to cats:
cats.addElement(new Dog2(7));
Enumeration e = cats.elements();
while(e.hasMoreElements())
((Cat2)e.nextElement()).print();
// Dog is detected only at run-time
}
}
class Cat2 {
private int catNumber;
Cat2(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat number " +catNumber);
}
}
class Dog2 {
private int dogNumber;
Dog2(int i) {
dogNumber = i;
}
void print() {
System.out.println("Dog number " +dogNumber);
}
}
返回目录 64 位 。这意味着假如我们准备保存比这更小的数据,如 8 位数据,那么 BitSet 就显得浪费了。所以最好创建自己的类,用它容纳自己的标志位。
返回目录 Stack 有时也可以称为“后入先出”(LIFO)集合。换言之,我们在堆栈里最后“压入”的东西将是以后第一个“弹出”的。和其他所有 Java 集合一样,我们压入和弹出的都是“对象”,所以必须对自己弹出的东西进行“造型”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/
public Stack() {
}
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public boolean empty() {
return size() == 0;
}
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1224463164541339165L;
}
以前就一直听说栈是后入先出,但只停留于理论记忆,其实根本不明白这是什么意思。现在看了Stack的源码实现就有点豁然开朗了。内部的push()以及pop()跟js太像了,我估摸着后入先出的实现就是靠着pop(),该方法默认删除数组最后一个元素,而元素又是通过push()放进去的,默认是放在数组最后一个,所以一直都说栈是后入先出 。栈顶其实就是数组最后一项。 注意!!! Stack并不要求其中保存数据的唯一性,当Stack中有多个相同的item时,调用search方法,只返回与查找对象equal并且离栈顶最近的item与栈顶间距离(见源码中search方法说明)。
返回目录 Vector 允许我们用一个数字从一系列对象中作出选择,所以它实际是将数字同对象关联起来了。但假如需要通过一个对象来查找呢?Dictionary 身上。该类的接口是非常直观的 size()告诉我们其中包含了多少元素;isEmpty()判断是否包含了元素(是则为 true);put(Object key, Object value)添加一个值(我们希望的东西),并将其同一个键关联起来(想用于搜索它的东西);get(Object key)获得与某个键对应的值;而remove(Object Key)用于从列表中删除“键-值”对。还可以使用枚举技术:keys()产生对键的一个枚举(Enumeration);而 elements() 产生对所有值的一个枚举。这便是一个Dictionary (字典)的全部。Dictionary 的实现过程并不麻烦。下面列出一种简单的方法,它使用了两个 Vector ,一个用于容纳键,另一个用来容纳值:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
package com.lizz.set;
import java.util.Dictionary;
import java.util.Enumeration;
import java.util.Vector;
public class AssocArray extends Dictionary {
private Vector keys = new Vector();
private Vector values = new Vector();
public int size(){
return keys.size();
}
public boolean isEmpty() {
return keys.isEmpty();
}
public Object put(Object key, Object value) {
keys.addElement(key);
values.addElement(value);
return key;
}
public Object get(Object key) {
int index = keys.indexOf(key);
if(index == -1) {
return null;
}
return values.elementAt(index);
}
public Object remove(Object key) {
int index = keys.indexOf(key);
if(index == -1) {
return null;
}
keys.removeElementAt(index);
Object returnvalue = values.elementAt(index);
values.removeElementAt(index);
return returnvalue;
}
public Enumeration keys() {
return keys.elements();
}
public Enumeration elements() {
return values.elements();
}
public static void main(String[] args) {
AssocArray aa = new AssocArray();
for(char c = 'a'; c < 'z'; c++) {
aa.put(String.valueOf(c), String.valueOf(c).toUpperCase());
}
char[] ca = {'a', 'e', 'i', 'o', 'u'};
for(int i = 0; i < ca.length; i++) {
System.out.println("Uppercase: " + aa.get(String.valueOf(ca[i])));
}
}
}
一个需要注意的示例 :1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
package com.lizz.set;
import java.util.Hashtable;
public class SpringDetector {
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
for(int i = 0; i < 10; i++) {
hashtable.put(new Groundhog(i), new Prediction());
}
System.out.println("hashtable = " + hashtable + "\n");
System.out.println("Looking up prediction for groundhog #3:");
Groundhog groundhog = new Groundhog(3);
/*
* Groundhog 是从通用的 Object 根类继承的(若当初未指定基础类,则所有类最终都是从Object 继承的)。
* 事实上是用 Object 的 hashCode()方法生成每个对象的散列码,而且默认情况下只使用它的对象的地址。
* 所以,Groundhog(3)的第一个实例并不会产生与Groundhog(3)第二个实例相等的散列码,而我们用第二个实例进行检索。
* 大家或许认为此时要做的全部事情就是正确地覆盖 hashCode()。但这样做依然行不能,除非再做另一件事情:覆盖也属于Object 一部分的 equals()。
* 当散列表试图判断我们的键是否等于表内的某个键时,就会用到这个方法。同样地,默认的 Object.equals()只是简单地比较对象地址,
* 所以一个 Groundhog(3)并不等于另一个 Groundhog(3)。因此,为了在散列表中将自己的类作为键使用,必须同时覆盖 hashCode()和equals(),
* 看示例 SpringDetector2
*/
if(hashtable.containsKey(groundhog)) {
System.out.println((Prediction)hashtable.get(groundhog));
}
}
}
class Groundhog {
int ghNumber;
Groundhog(int n) {
ghNumber = n;
}
}
class Prediction {
boolean shadow = Math.random() > 0.5;
public String toString() {
if(shadow)
return "Six more weeks of Winter!";
else
return "Early Spring!";
}
}
SpringDetector2.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package com.lizz.set;
import java.util.Hashtable;
public class SpringDetector2 {
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
for(int i = 0; i < 10; i++) {
hashtable.put(new Groundhog2(i), new Prediction());
}
System.out.println("hashtable = " + hashtable + "\n");
System.out.println("Looking up prediction for groundhog #3:");
Groundhog2 groundhog2 = new Groundhog2(3);
if(hashtable.containsKey(groundhog2)) {
System.out.println((Prediction)hashtable.get(groundhog2));
}
}
}
class Groundhog2 {
int ghNumber;
Groundhog2(int n) {
ghNumber = n;
}
public int hashCode() {
return ghNumber;
}
public boolean equals(Object o) {
return (o instanceof Groundhog2) && (ghNumber == ((Groundhog2)o).ghNumber);
}
}
返回目录 String.class里面的compareTo()方法。那就看看源码吧:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private final char value[];
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
compareTo()接受一个String类型参数,由于涉及到了强转相当于new String("参数")调用了String的带String类型参数的构造器,这样value就有值了。而value初始化是一个char类型的数组,所以具有length属性。接下来比较调用compareTo()的String与传入的String参数长度并取较小的值。然后利用while()循环从数组下标为0开始进行比较,如果全部相等返回长度的差值0 ,如果数组元素中有一个不相等,则返回相应的ASCII码 相减后的值(第一个参数大于第二个那就返回正整数,小于的话返回负整数 )。
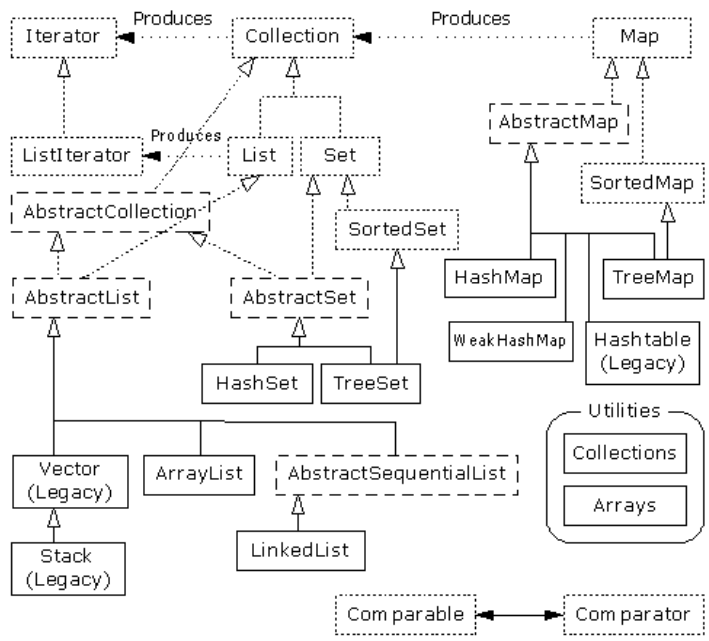
返回目录 Collection):一组单独的元素,通常应用了某种规则。在这里,一个 List(列表)必须按特定的顺序容纳元素,而一个Set(集)不可包含任何重复的元素。相反,“包”(Bag)的概念未在新的集合库中实现,因为“列表”已提供了类似的功能。Map):一系列“键-值”对(这已在散列表身上得到了充分的体现)。从表面看,这似乎应该成为一个“键-值”对的“集合”,但假若试图按那种方式实现它,就会发现实现过程相当笨拙。这进一步证明了应该分离成单独的概念。另一方面,可以方便地查看 Map 的某个部分。只需创建一个集合,然后用它表示那一部分即可。这样一来,Map 就可以返回自己键的一个Set、一个包含自己值的List 或者包含自己“键-值”对的一个List。和数组相似,Map 可方便扩充到多个“维”,毋需涉及任何新概念。只需简单地在一个Map 里包含其他 Map(后者又可以包含更多的Map,以此类推)。
这张图刚开始的时候可能让人有点儿摸不着头脑,但在通读了本章以后,相信大家会真正理解它实际只有三个集合组件:Map,List 和 Set 。Iterator),而一个列表可以生成一个ListIterator(以及原始的反复器,因为列表是从集合继承的)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package com.lizz.set;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class SimpleCollection {
public static void main(String[] args) {
Collection c = new ArrayList();
for(int i = 0; i < 10; i++) {
c.add(Integer.toString(i));
}
Iterator it = c.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
查了下源码,发现Collection接口定义了add()以及iterator()等方法,而ArrayList实现了List接口,List接口继承自Collection,其实也就是ArrayList变相的实现了Collection接口里的方法。
上述代码while循环用到了hasNext(),Iterator是一个接口,我查了下ArrayList以及Collection并没有明确继承或实现该接口,然后在Collection里的确找到了iterator()方法,然后又在ArrayList里找到了该方法的实现:
1
2
3
4
5
6
7
8
9
10
11
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
...
由源码可以看出,iterator()返回一个Itr类的实例,而该类实现了Iterator接口。在该类内部,它重写了或者说覆盖实现了hasNext()。
返回目录
下面给出Thinking in Java示例中的部分代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public class Collection1 {
public static Collection fill(Collection c, int start, int size) {
for(int i = start; i < start + size; i++) {
c.add(Integer.toString(i));
}
return c;
}
public static Collection fill(Collection c) {
return fill(c, 0, 10);
}
public static Collection newCollection() {
return fill(new ArrayList());
}
public static Collection newCollection(int start, int size) {
return fill(new ArrayList(), start, size);
}
public static void print(Collection c) {
for(Iterator x = c.iterator(); x.hasNext();) {
System.out.println(x.next() + " ");
}
System.out.println();
}
public static void main(String[] args) {
Collection c = newCollection();
c.add("ten");
c.add("eleven");
c.addAll(newCollection());
print(c);
Collection c2 = newCollection(5, 3);
c.retainAll(c2);
print(c);
c.removeAll(c2);
}
}
上述代码我在本地打印输出到了c.retainAll(c2);这一步有点不懂了。先是点进去查看了ArrayList.class里面的retainAll()方法的实现,发现它返回的是batchRemove()方法,看了下batchRemove(),一开始看不下去就去百度了。百度得知retainAll()是用来取交集 的,结合控制台输出我知道这种解释是对的,但是百度还来了句removeAll()也调用了batchRemove()方法,这我就有点懵了。我就好奇他是怎么实现的呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
protected transient int modCount = 0; // 这里是继承自AbstractList,并不是ArrayList内定义的
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
研究batchRemove()内部的实现首先要知道elementData以及size,所以我把这两个变量初始化以及赋值相关的方法也贴出来了。Collection c = newCollection();这一步调用了newCollection()方法,而该方法内部返回了fill(new ArrayList()),我们知道ArrayList()其实实现了Collection接口,所以这一步调用的是public static Collection fill(Collection c)这个对应的fill方法。该方法内部又返回了fill(c, 0, 10),这里其实是调用public static Collection fill(Collection c, int start, int size)这个对应的方法,然后利用该方法对c进行add元素并返回c。
其实示例中一开始的Collection c = newCollection();实际相当于Collection c = new ArrayList(),这一步实例化了ArrayList,那么同样的会调用它的构造方法。在构造方法里,给elementData初始化赋值为DEFAULTCAPACITY_EMPTY_ELEMENTDATA(空对象集合)。
历经几步调用终于到了正主public static Collection fill(Collection c, int start, int size),在该方法内使用了add()方法,也正是调用了add(),elementData以及size才开始赋值改变的。
add()内的第一步就调用了ensureCapacityInternal(size + 1),那么size从何而来呢?其实size在初始化时就定义了但是没有赋值,这里采用了默认值0 。观察ensureCapacityInternal()方法,使用minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity)比较它们两个中较大的值并重新赋给minCapacity,DEFAULT_CAPACITY是常数设定为10比1大所以经过该方法后,minCapacity的值被改为10 。随后又调用了ensureExplicitCapacity()方法。在ensureExplicitCapacity()里判断传过来的值是不是比elementData的长度大,是的话继续调用grow(minCapacity)。
grow()方法是重点(容量增长算法)。摘抄自 https://www.cnblogs.com/aoguren/p/4765439.html
先得到数组的旧容量,然后进行oldCapacity + (oldCapacity >> 1),将oldCapacity 右移一位,其效果相当于oldCapacity /2,我们知道位运算的速度远远快于整除运算 ,整句运算式的结果就是将新容量更新为旧容量的1.5倍 。
然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量.
再检查新容量是否超出了ArrayList所定义的最大容量,若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为 minCapacity。(在判断容量是否超过MAX_ARRAY_SIZE的值,MAX_ARRAY_SIZE值为Integer.MAX_VALUE - 8 ,比int的最大值小8,不知道为什设计,可能方便判断吧。如果已经超过,调用hugeCapacity方法检查容量的int值是不是已经溢出。)
最后确定了新的容量,就使用Arrays.copyOf方法来生成新的数组,copyOf也已经完成了将就的数据拷贝到新数组的工作。
通过上面的方法,完成了elementData的重新赋值,接下来在看batchRemove()就容易很多了。batchRemove()里面的c 其实是我传进来的c2 ,循环遍历elementData ,然后结合complement同时利用contains()来判断c 中是否存在elementData中的元素,如果complement为true,同时c 中也存在elementData中的元素,那么对elementData重新赋值(从下标为0开始 )。最后通过finally判断w是不是和size相等,不等的话将elementData中多余的参数给清空掉。(w其实就是c的长度 )
返回目录 List、ArrayList、LinkedList 。
返回目录 Set、HashSet、TreeSet 。添加到 Set 的每个元素都必须是独一无二的;否则Set 就不会添加重复的元素 。添加到 Set 里的对象必须定义equals(),从而建立对象的唯一性 。Set 拥有与 Collection 完全相同的接口。一个 Set不能保证自己可按任何特定的顺序维持自己的元素。hashCode()
返回目录 Map、HashMap、TreeMap https://www.cnblogs.com/skywang12345/p/3310835.html
返回目录 sort和binarySearch方法。sort我重开了一篇博客去研究它的源码实现,接下来的binarySearch方法一开始我没在意,直到我仔细研读书上的文字,发现它强调了:
与 binarySearch()有关的还有一个重要的警告:若在执行一次binarySearch()之前不调用 sort(),便会发生不可预测的行为,其中甚至包括无限循环。
这段话的意思无非就是使用binarySearch前必须先调用sort进行排序。这样就很有趣了,我便去看看它的源码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public static int binarySearch(byte[] a, byte key) {
return binarySearch0(a, 0, a.length, key);
}
private static int binarySearch0(byte[] a, int fromIndex, int toIndex, byte key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
byte midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
Array1.java:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
public class Array1 {
static Random r = new Random();
static String ssource = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" + "abcdefghijklmnopqrstuvwxyz";
static char[] src = ssource.toCharArray();
public static String randString(int length) {
char[] buf = new char[length];
int rnd;
for(int i = 0; i < length; i++) {
rnd = Math.abs(r.nextInt()) % src.length;
buf[i] = src[rnd];
}
return new String(buf);
}
public static String[] randStrings(int length, int size) {
String[] s = new String[size];
for(int i = 0; i < size; i++) {
s[i] = randString(length);
}
return s;
}
public static void print(byte[] b) {
for(int i = 0; i < b.length; i++) {
System.out.println(b[i] + " ");
}
System.out.println();
}
public static void print(String[] s) {
for(int i = 0; i < s.length; i++) {
System.out.print(s[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
byte[] b = new byte[15];
r.nextBytes(b);
print(b);
Arrays.sort(b);
print(b);
int loc = Arrays.binarySearch(b, b[10]);
System.out.println("Location of " + b[10] + " = " + loc);
String[] s = randStrings(4, 10);
print(s);
Arrays.sort(s);
print(s);
loc = Arrays.binarySearch(s, s[4]);
System.out.println("Location of " + s[4] + " = " + loc);
}
}
源码中有(low + high) >>> 1这句代码,不明白的可以看:https://lizhongzhen11.github.io/2018/04/02/%E4%BD%8D%E8%BF%90%E7%AE%97%E7%AC%A6%E8%AE%A1%E7%AE%97%E5%B9%B3%E5%9D%87%E5%80%BC/ 该数组是从小到大排列好的,因为它不断地用中间下标对应的值与传入的值进行比较,它认为,如果中间值比传入的小或者大,那么通过不断地缩短开始和结束下标范围就一定能找到传入值,这一切的前提都必须是排序好的。
返回目录 抄自:http://www.importnew.com/23708.html
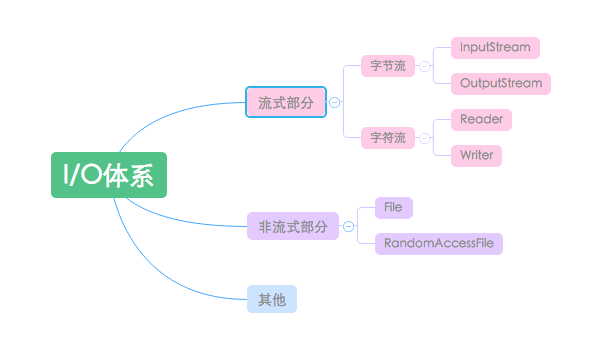
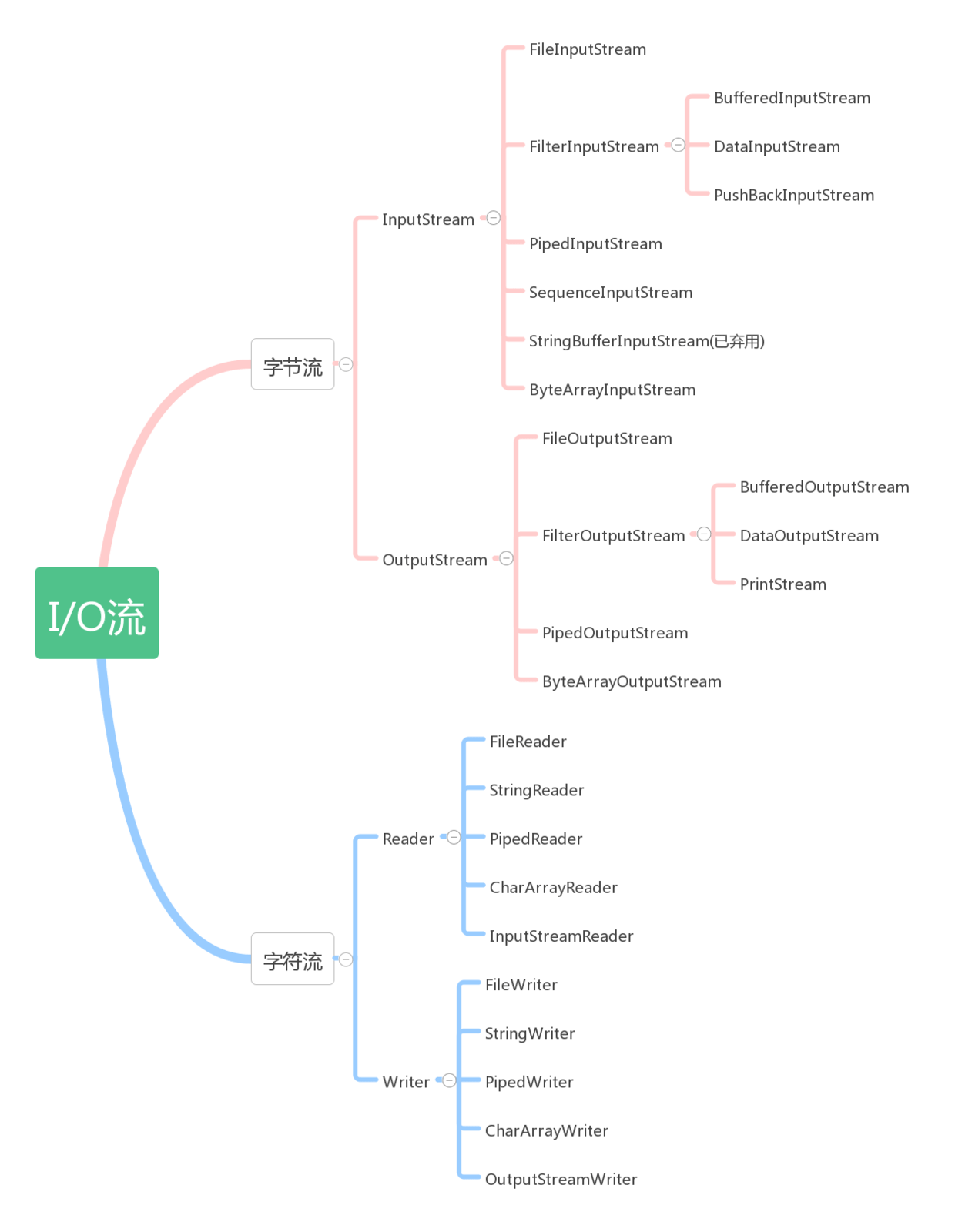
流序列中的数据既可以是未经加工的原始二进制数据,也可以是经一定编码处理后符合某种格式规定的特定数据。因此Java中的流分为两种:
Java.io包中最重要的就是5个类和一个接口。5个类指的是File 、OutputStream 、InputStream 、Writer 、Reader ;一个接口指的是Serializable 。
Java I/O主要包括如下3层次:
流式部分——最主要的部分。如:OutputStream、InputStream、Writer、Reader等
非流式部分——如:File类、RandomAccessFile类和FileDescriptor等类
其他——文件读取部分的与安全相关的类,如:SerializablePermission类,以及与本地操作系统相关的文件系统的类,如:FileSystem类和Win32FileSystem类和WinNTFileSystem类。
主要类如下:
File(文件特征与管理):用于文件或者目录的描述信息,例如生成新目录,修改文件名,删除文件,判断文件所在路径等。
InputStream(字节流,二进制格式操作):抽象类,基于字节的输入操作,是所有输入流的父类。定义了所有输入流都具有的共同特征。
OutputStream(字节流,二进制格式操作):抽象类。基于字节的输出操作。是所有输出流的父类。定义了所有输出流都具有的共同特征。
Reader(字符流,文本格式操作):抽象类,基于字符的输入操作。
Writer(字符流,文本格式操作):抽象类,基于字符的输出操作。
RandomAccessFile(随机文件操作):它的功能丰富,可以从文件的任意位置进行存取(输入输出)操作。
返回目录 http://www.cnblogs.com/xrq730/p/4850883.html TestThread.state里面定义了6种状态,分别是:
NEW:线程刚创建,还未启动
RUNNABLE:就绪状态。当调用了start()方法时就进入该状态。
BLOCKED:如果某一线程正在等待监视器锁,以便进入一个同步的块/方法,那么这个线程的状态就是阻塞BLOCKED
WAITING:某一线程因为调用不带超时的Object的wait()方法、不带超时的Thread的join()方法、LockSupport的park()方法,就会处于等待WAITING状态
TIMED_WAITING:某一线程因为调用带有指定正等待时间的Object的wait()方法、Thread的join()方法、Thread的sleep()方法、LockSupport的parkNanos()方法、LockSupport的parkUntil()方法,就会处于超时等待TIMED_WAITING状态
TERMINATED:线程调用终止或者run()方法执行结束后,线程即处于终止状态。处于终止状态的线程不具备继续运行的能力